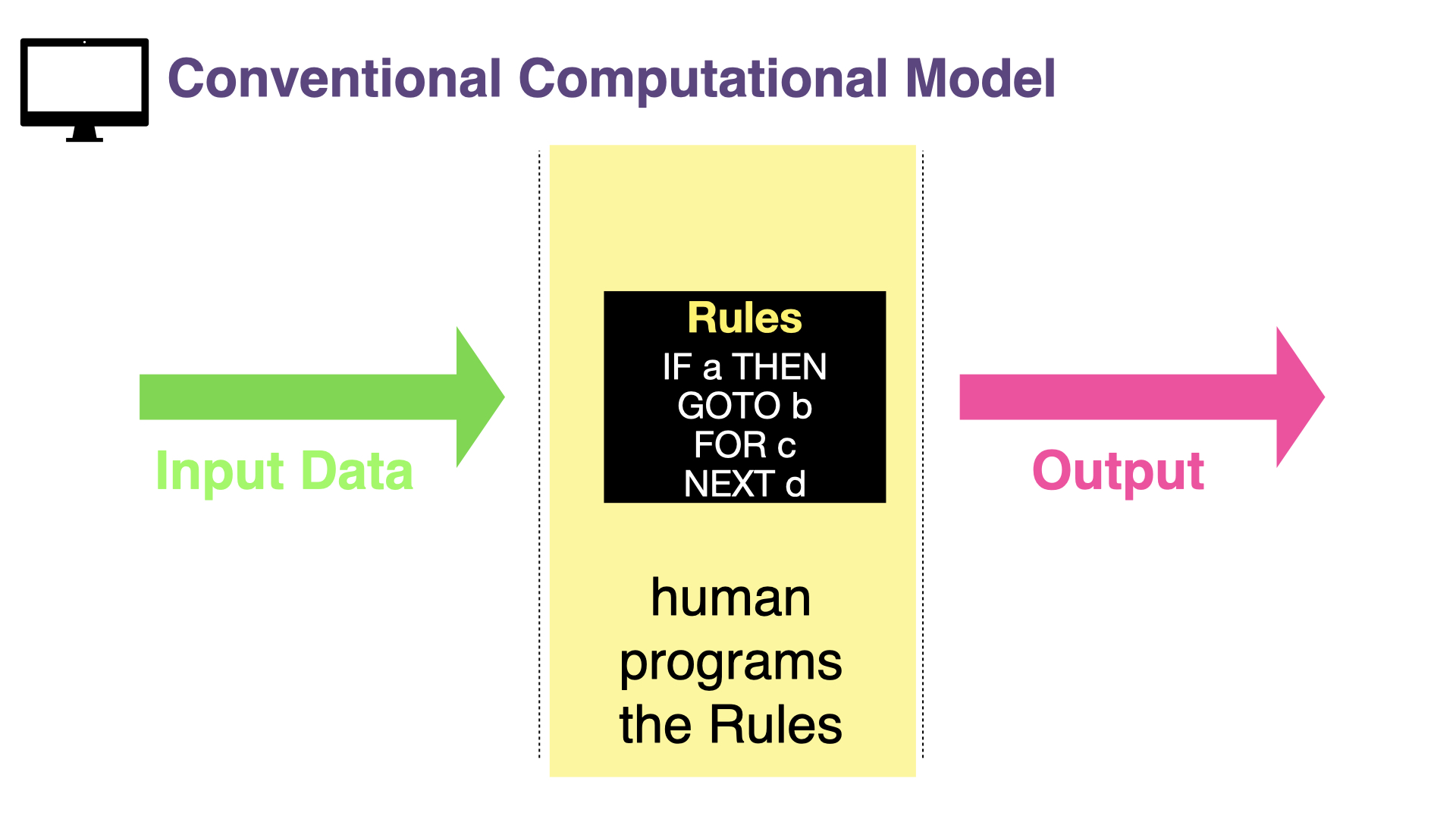
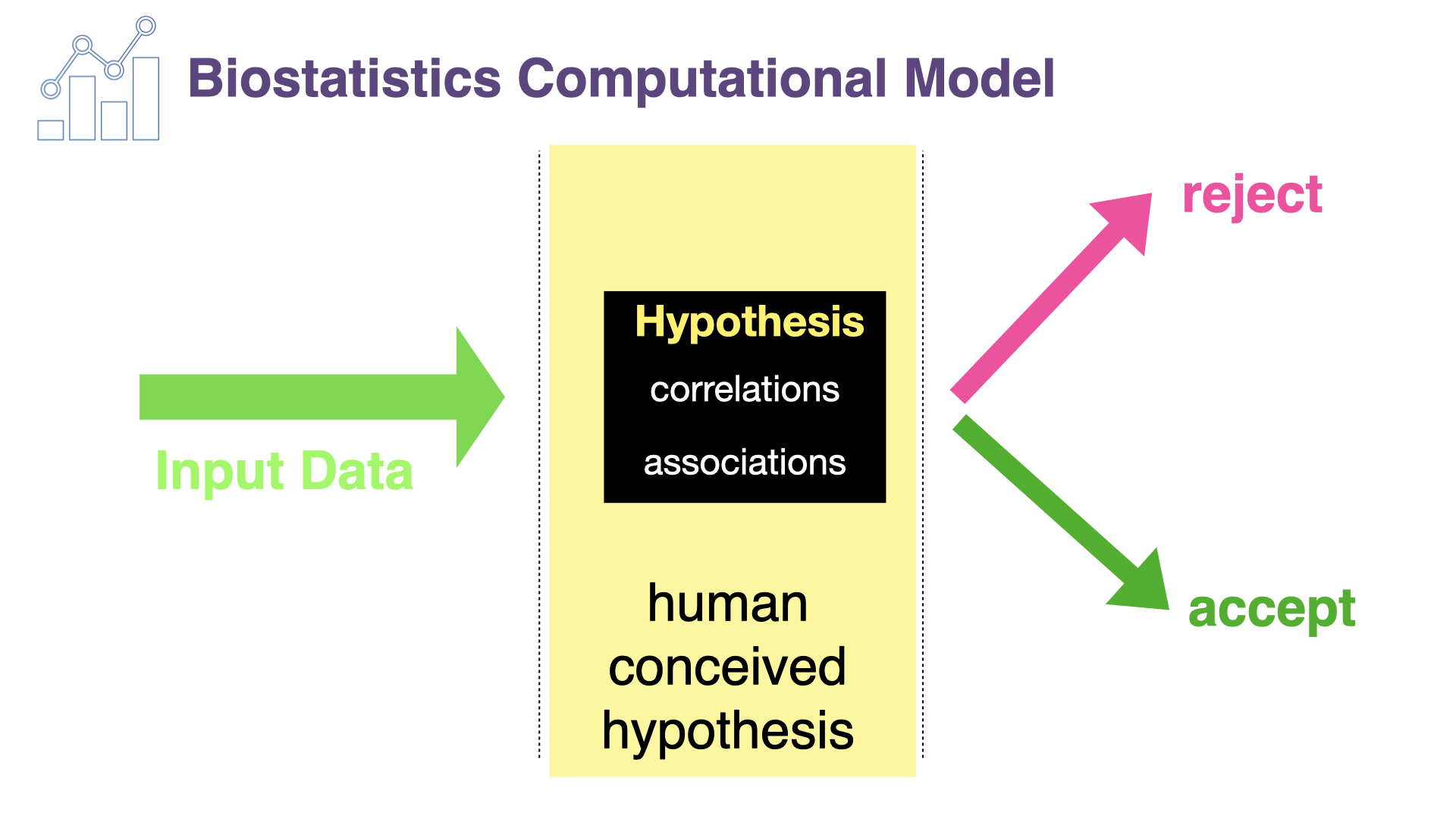
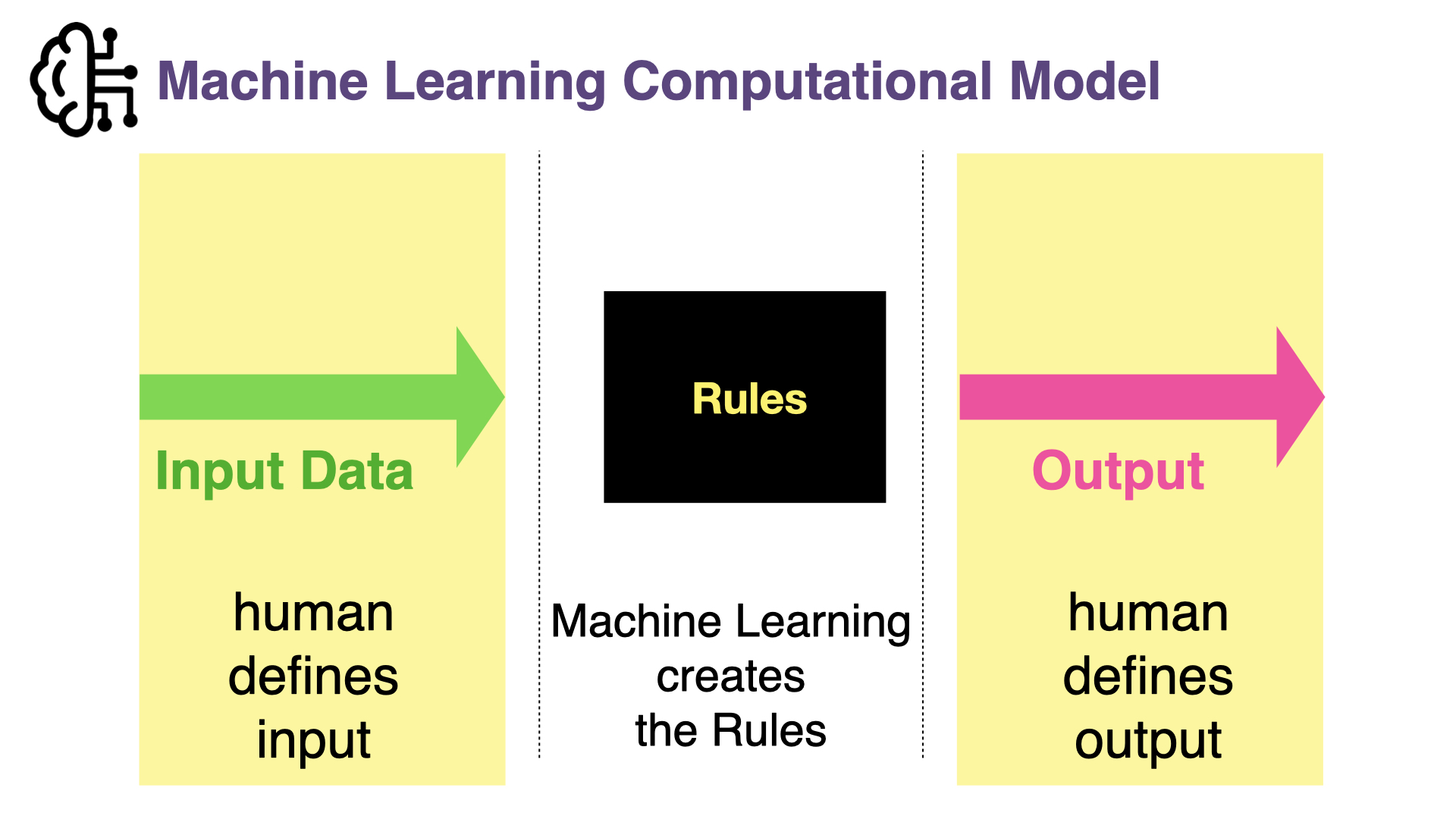
{kind=link}

Spot the hidden tank!
There is a widely spread anecdote among AI communities about the US military developing a machine learning algorithm which could identify camouflaged enemy tanks hidden in a forest. Photos of US and enemy tanks were fed in the machine learning model, , from different angles and views. The developers soon were excited to confirm that the machine learning algorithms could effectively distinguish between US and enemy tanks with very high precision, when however the software was tested by the army it failed to perform. Looking back to the training process, they then realised that the photos with the US tanks were taken in good conditions and ample sunlight, while the photos of the enemy tanks were mainly spycam snapshots from frontlines, taken in winter or cloudy conditions. The machine learning algorithm learned to distinguish between weather patterns and brightness in the photo, rather than the actual type of tanks... Regardless of the authenticity of the story, this issue is very concerning and has been repeatedly observed in machine learning applications in healthcare as well.
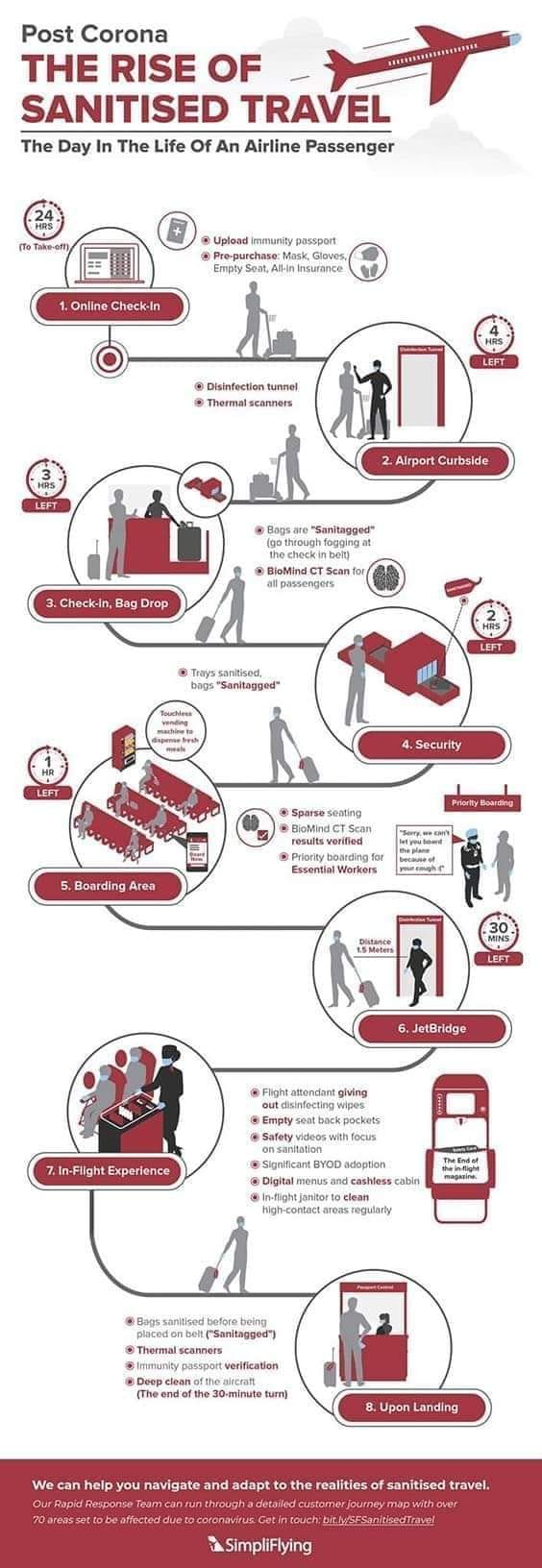
Covid-19 and Machine Learning Algorithms
Back in May 2020, with Covid-19 everywhere on the rise and scarce resources to diagnose it, there was tremendous pressure for quick diagnostic or screening tests, which AI applications were hastily developed to satisfy. Several Machine Learning algorithms were trained to recognise signs of covid in chest radiographs and CT scans, scoring high in internal metrics of performance. On the basis of these, some advocated the fast implementation of mass scale CT-scans to air travelers as a quick and efficient screening. Luckily the dystopian travel process described in the image was never implemented. Only later was it actually shown that none of these algorithms was any good, despite promising internal precision. A paper in Nature Machine Intelligence (Roberts et al 2021) concluded that not one of the 62 models reviewed was any good in actual clinical application, with most of the flaws being identified in the process that was used to train the algorithms, which was plagued by deficiencies and bias. In one case for example the positive covid patients used to train the model were all bedridden, while the healthy controls were standing. The algorithm showed high internal precision in detecting Covid-19 on the basis of chest radiographs, but failed to perform in actual clinical setup. It was then realised that the algorithm had learned to identify if the patient was in lying or standing position, rather than the Covid-19 status.
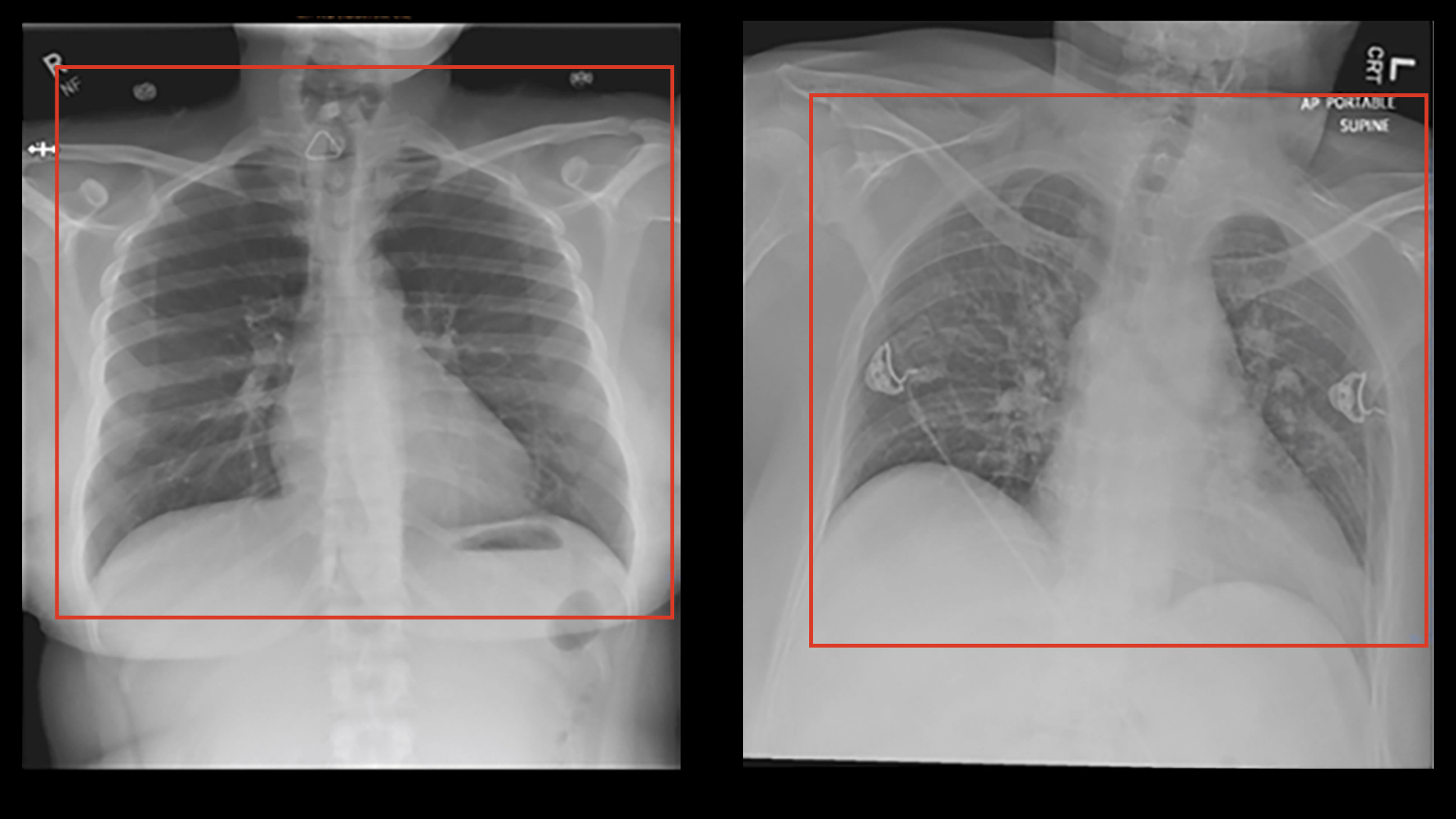
Spot the ...x differences..!
Bedridden patients were frequently x-rayed with portable devices and under different settings. The patients' position was not as symmetrical as the standing patients, with slight rotations and irregular placement in the frame. The radiographs were also sometimes marked with text indicating portable device and subpine position. In a very cool demonstration of street-smart intelligence, the machine learned how to pass the exam, but never really learned the content...! This can be a typical case of what we call "overfit" algorithms, where the machine learning has evaluated too specific patterns in the training sample, including irrelevant ones and noise, thus becomes increasingly unable to detect relevant patterns in new samples, although highly successful in the training samples.
2 thoughts on “Artificial Intelligence, Machine Learning and Implant Dentistry!”
thank you for your insights! Indeed there are too many claims of “AI” in software and devices, hard to understand what it means…is there no requirements or anyone can just claim that his product includes or uses AI?
nice article.thanks